
- 说明
- 分类:驱动研发
- 点击数:115
声音的概念?
先和各位一起简单科普一下概念知识,声音是由物体振动产生的声波,是通过介质(空气或固体、液体)传播并能被人或动物听觉器官所感知的波动现象。一般由响度、音调及音色这么三个属性来衡量声音如何如何
- 响度:人主观上感觉声音的大小,由振幅和人离声源的距离决定,振幅越大响度越大,人和声源的距离越小,响度越大
- 音调:声音的高低,由频率决定,频率越高音调越高
- 音色:声音的特性,由发声物体本身材料,结构决定
上述就是声音的一个简单概念,欲知如何与我今天讲的程序中的数字音频技术相关联,请继续往下看哟
音频是啥?
我们知道声音是由物体振动产生的,当声音改变了人耳鼓膜上空气的压力时,这时人耳就听到声音了。所以我们在向麦克风说话时,麦克风设备能感应到这些振动,并且将它们转换为电流。同样,电流再经过放大器和扩音器,就又变成了声音。声音的振动可以用正弦波表示,其中波的振幅决定音量(即声音的响度),频率决定音调。人耳可以感受的频率范围是20HZ ~ 20000HZ(用分贝表示:0~120 db,二者之间如何换算这里不做说明,感兴趣的自己去科普)的,而且感受的频率变化关系是呈对数关系,并非是线性关系。也就是说20HZ到40HZ和40HZ到80HZ的变化,人耳感受是一样的。在音乐中,把这种加倍的频率定义为八度音阶(想继续了解,请自行科普),具体应用见文章最后技术拓展及应用。
计算机都本质是处理二进制数据,也就是说任何东西在计算机中的表现都是一堆二进制数值。所以计算机中的音频又叫数字音频。那么现在需要一种方法将自然界中的声音(即振动)输入到计算中进行处理,那么这种方法是什么呢?就是PCM(即脉冲编码调制,我这里说的PCM和下文中的PCM文件格式不是一回事),概括来说这种方法就可以将外界的物理声音和计算机的电信号(高低电平)之间的相互转换。所以麦克风设备实质执行的是将物理声音转换为电信号,扬声器设备实质执行的是将电信号转换为物理声音。那么计算机的电信号可以用二进制表示,即音频数据就是一堆用二进制表示的数据。至于麦克风设备和扬声器设备具体如何进行转换的,这里不做说明,如果想继续详细深挖,请自行科普噢。
既然我们知道音频数据是一堆用二进制表示的数据,那么声音其他属性如何控制(音质,音量等)。首先这里需要说明的是,控制音频的三个固有参数:采样率,通道,位深。在具体讲述三个参数前,先给一些音频属性计算公式:
- 采样点大小:通道 * 位深 / 8 (B/s)
- 样数:采样频率 (个/s)
- 时长:采样数 / 采样点大小 * 1000 (ms)
- 分贝:(db)见下图(至于如何使用计算,详情讲解见文章最后链接地址)

采样率?单位:HZ。常见的有48000,44100,22500,8000等。如果音频采样率为48000HZ,也就是说这段音频每秒有48000个采样点。采样点数量越高,声音越精确。这里直接和声音的音调属性相对应。这里说的采样频率就是上面说的人耳频率,那么为什么48000HZ人耳还可以听见?其实这里的频率和实际人耳听到频率是有出入的,因为在计算机实际处理的时候是有对应的关系(具体关系自己去科普把),导致最后的采样频率看起来远远超过人耳接受的频率范围。
通道?常见的有单通道,双通道(即立体声)。这里有一个定义容易混淆,需要说明一下(本人最开始就弄混了)。通道和声道是两个东西,通道数和音轨数对等。所以这就是为什么单通道的音频为什么左右耳机还是会有声音。通道和音轨对于波形(wav)音频,可以使用audacity软件分析,见下图(双通道的wav音频格式文件):
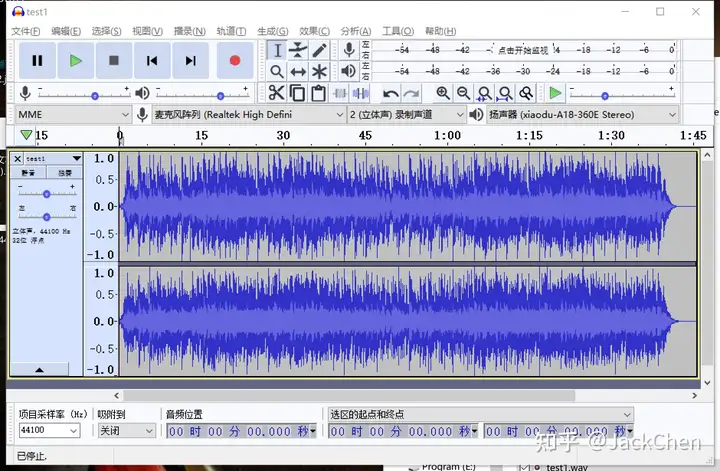
初次看见这种图,是不是很蒙逼。哈哈,没关系,我在下面会具体进行说明(为什么声音是这种波形图)。还有就是我们常说的5.1声道(6通道),3D环绕(4通道),这些多通道的音频一般由专门设备和音频工具而制作。像我们常规的电脑一般只可录制单通道和通道的。不过尽管录制不了高通道声音,后期是可以通过程序计算出高声道的声音。音轨数越多,声音越有层次感。
位深?单位:b。又称量化。常见的有8位,16位,32位等。分有无符号、有符号、整型及浮点型。一般浮点型用于超过16位以上的音频,用于浮点数。量化值越大,声音的振幅范围越大,质量越高。
下面针对上述audacity软件的波形图进行简要说明。假设现在分析的一段采样率为48000HZ,2通道,16位深的有符号音频,我把上述的图进一步放大,见下图:

那么横轴其实就是时间轴,取样点是48000(就是音频的频率),那么纵轴值(即振幅)如何计算?16位的有符号数取值范围为:[-32768,32767](这里说明一下,根据这个振幅值可以计算声音的分贝),这里我用的这个软件,都将范围适配到-1.0到1.0了。但是这个不影响最后结果,只是表现而已。上下两个波形图,分别表示两个通道(即音轨)。所以到这里,是不是知道声音为什么是波形图了,或者说为什么用波形图表示了吧!没有想的那么难噢!
PCM数据?帧、流和文件?
我们常说的音频原始数据就是说的PCM数据,由3个参数衡量(就是上述的采样率,通道及位深)。那么PCM数据是什么格式,怎么解析呢?PCM数据如果是单通道的话,就逐个按照采样点大小读取就行了。如果针对多通道,就分两种情形:
- 顺序排列方式:每个通道按顺序存储,解析的时候逐个通道进行解析
- 交叉排列方式:每个采样点存储都是按照通道顺序进行存储的(常见的排列方式)
为了更加直观,见下图说明:

PCM文件数据是不可直接用于常见播放器播放的,因为PCM数据的采样率,通道数和位深这个三个参数是通过解析文件是不知道的,是需要显示指定的。VLC播放软件是可以播放PCM文件的,但也是需要人为指定PCM三个参数的,所以还是不可直接播放。
那么PCM文件如何播放呢?和其他MP3、WAV等直接可用于播放的音频文件又有什么联系呢?我们现在知道了要想播放PCM数据文件,需要让播放器知道PCM文件的三个参数,所以我们需要把PCM数据的三个参数整合到一个文件中,这样才可以直接通过文件直接进行解析出当前需要播放的文件的具体属性。所以只需要在PCM文件加上一个头部即可(这个头部至少包含衡量其的三个参数),这也就是WAV文件,wav文件数据流就是由一个头部和PCM数据组成(具体格式,谷歌百度上的资料很多)。
这里有的同僚可能会有疑问?我直接加上这个三个参数不行么,为什么还要像WAV文件包含了其他参数?直接加上三个参数当然可以,但是这是你自定义的可播放PCM文件标准,但是通用播放器并不会去识别,除非你自己开发播放器和生成你自定义的PCM音频文件。所以凡事都得标准化,微软在这里给出了一种基于PCM数据播放的文件格式标准WAV,并且外界也认可。这就是为啥很多东西要标准化,有了标准大家才会有参考,以这个为标准的技术应用才会越来越多啊
MP3文件呢?和WAV文件一样,也是一种可播放的文件格式。数据流也是由头部和数据组成。不过这个数据不是PCM数据,而是MP3编码数据(由PCM数据编码而来,何为编码见下文)。在播放的时候就多了一个解码步骤,需要先把MP3编码数据解码成PCM数据在输入播放器中。
上面已经提到了MP3文件和WAV文件两种可播放格式。这里需要给各位详细说明一下相关知识。在计算机中,一般音频数据不可直接用于播放的(这是相对于播放器而言),要想播放需要为音频数据加头!常见可以直接播放音频文件类型有:wav,flac,aac,ape,wma,mp3,ogg,m4a等格式。尽管这些格式是常见的格式,但是除了部分格式的资料很多,其他类型资料很少,而且网上有很多说法不一!所以要想把这几种类型的文件头部和数据解析出来,不是一件易事,需要根据网上残缺资料和逆向分析音频数据。庆幸的是我对这几种常见的类型都进行解析了(自夸一下,嘿嘿),不过花了很大的时间和功夫。文章最后我会给出wav和flac类型文件组成结构,之所以不全给也请诸位体谅下本人的知识产权,暂不对外!
我们知道了每个播放的文件都由头部和音频数据组成。但音频数据随着各种类型的文件,又分为其他几种形式(具体类型解释见下文):
- 原始数据(PCM):wav
- 无损压缩:flac,ape
- 有损压缩:aac,wma,mp3,ogg,m4a
不管无损或有损,每种类型压缩算法都不一样。想要继续深挖解压缩原理(即编解码原理),请自行百科!
搞清了可播放的音频文件之后,那么需要在搞清楚流和帧是个什么玩意了?流其实很简单,上述说的可播放的音频文件去掉头之后的音频数据就叫做流。流这个称谓常见在音视频领域,诸如音频流,视频流之类的话术,说的就是这么个玩意。还需要给各位说明的一点是,可能各位会听到可播放的音频流和不可播放的音频流,这两者又是个什么东东?这里请各位记住的一点是如果音频流直接可用于播放,他一定是加了头的(这个头不一定和上述可播放文件中的头完全一样,但一定包含了用于播放的三个参数)。
什么又是帧呢?音频中的帧没有准确定义。根据不同的类型格式有不同的定义和说法。音频中的帧不像视频中的帧那样定义很明确,一帧就是一副图像。尽管如此,还是需要和各位说明一下的。在PCM音频数据中,音频帧有两种说法:一是一个音频帧通常指一个采样点大小;二是一个音频帧用多长时间(这个时间没有标准)。在其他非PCM数据中,音频帧有固定大小的,非固定大小的,还有一种固定时长的。针对非固定的大小和固定时长的音频帧类型,需要实时解析才可知道音频帧的实际大小。
编解码是啥?为什么要编解码?
编解码通俗点讲就是压缩和解压缩,就是换了个说法而已,给人的感觉比较高级。其实吧,并没什么卵用(我个人觉得通熟易懂就行),编解码称呼常用于音视频相关和嵌入式部分开发中(本人知道的)。音频编解码到底是啥呢?把音频原始数据(PCM)编码为其他格式(aac、mp3、opus等)的数据这一过程称为编码过程(压缩);把音频编码后的格式数据解码为原始数据(PCM,注意这里说的原始数据PCM,并非和编码前的PCM数据完全一样,也可能不一样,因为分为无损和有损两种,详情见下)称为解码过程(解压缩)。
无损压缩是将原数据压缩后,通过解压缩过程后的数据和原数据完全一样;有损压缩是将原数据压缩后,通过解压缩过程后和原数据高度相似而已(这里说的相似是针对具体环境和特征值的)。有损压缩的压缩率远远高于无损压缩
无损压缩常用于文件、重要数据资料等,各位可以直观想一下,如果压缩后的文件等数据是有损的,那么还原回来的数据就被破坏了,就没啥意义了。有损压缩常用于音频、视频、图像等,就拿图像来说,对大多数情况而言人们只需要觉得图像清晰就行,人的肉眼是感性的
可能有的同僚会问到,音频为什么要编解码(解压缩),直接处理不好么,而且还不会有音质损坏,速度也会更快。我想说的是音频编解码(解压缩)其中最主要的一个作用是最大化利用空间资源、还有就是起一定的加密作用。先说一个现象,国内计算机流行起来,大概在20世纪末21世纪初左右,也就是2000年左右,那会本人才5岁(有点暴露年龄了)。本人最开始接触计算机大概10岁左右,当时用的存储介质sd卡,还有软盘,只有几兆(大众化使用)。假设一段时长4分钟、采样率48000HZ,双通道,16位整型的PCM原始音频需要的空间:4 * 60 * 48000 * 2 * 16 / 8 = 45000 KB(约44MB),估计那会的mp3和随身听,存不了几首歌吧。尽管今天各存储介质基本都是以GB为单位了,但是如果音频不经过编码,依然会占用很大空间,这还仅仅是音频,未经编码的图片和视频占用空间更大。(本篇对图片和视频不做说明)
重采样?混流?增减益?
重采样实质就是改变现有音频参数(采样率,通道,位深)。例如:要把采样率为48000HZ,2通道,16位深的音频数据转换为采样率为22500HZ,1通道,16位深的音频数据。这个过程就叫做重采样,也就是说只要任一音频参数发生转换的过程就叫做重采样。这里分别针对采样率、通道及位深三个参数分别说明:
采样率重采样,只需要把源采样率适配到目的采样率就行了,根据二者相比的系数从而确定出重采样后音频的采样点数,然后根据插值方程:outData=(1-coe)*inData + coe*inData计算。下面给出1通道8位的x HZ到y HZ的部分代码:
//这里各个形参各位应该能对应上,这里不做说明
void reSampleFreq(unsigned long inFreq, unsigned char* inData, unsigned long inLen, unsigned long outFreq, unsigned char* &outData, unsigned long &outLen, unsigned short bits, unsigned short channels)
{
outLen = (unsigned long)(inLen * (double)outFreq / inFreq);
outData = new unsigned char[outLen];
int bitBytes = (int)(bits / 8);
int pointBytes = (int)(bitBytes * channels);
unsigned long inSamplePonits = inLen / pointBytes;
unsigned long outSamplePonits = outLen / pointBytes;
unsigned char* ptInData = (unsigned char*)inData;
unsigned char* ptOutData = (unsigned char*)outData;
for (unsigned long i = 0; i < outSamplePonits; i++) {
double index = (double)i * inFreq / outFreq;
int point1 = (int)index;
int point2 = (inSamplePonits - 1 == point1) ? (inSamplePonits - 1) : point1 + 1;
double coe = index - point1;
ptOutData[i] = (unsigned char)((1.f - coe) * ptInData[point1] + coe * ptInData[point2]);
}
}
通道重采样,如果是单通道到多通道,只需把单通道数据拷贝多份,按照上面说的PCM数据排列方式即可;如果是多通道到单通道,只保留其中任何一条通道数据就行了。下面给出任意采样率频率8位的1通道到2通道的部分代码:
//这里各个形参各位应该能对应上,这里不做说明
void reSampleChannel(unsigned short inChannel, unsigned char* inData, unsigned long inLen, unsigned short outChannel, unsigned char* &outData, unsigned long &outLen, unsigned long freq, unsigned short bits)
{
outLen = (unsigned long)(inLen * (double)outChannel / inChannel);
outData = new unsigned char[outLen];
int bitBytes = (int)(bits / 8);
int inBitBytes = (int)(bitBytes * inChannel);
int outBitBytes = (int)(bitBytes * outChannel);
unsigned long inSamplePonits = inLen / (inBitBytes * inChannel);
unsigned long outSamplePonits = outLen / (outBitBytes * outChannel);
unsigned char* ptInData = (unsigned char*)inData;
unsigned short* ptOutData = (unsigned short*)outData;
for (unsigned long i = 0; i < outSamplePonits; i++) {
ptOutData[i] = ptInData[i];
ptOutData[i] <<= 8;
ptOutData[i] |= ptInData[i];
}
}
位深重采样,比如无符号的8位(取值范围为[0, 255])到16位(取值范围为[0,65535]),就是把二者范围差值相比,每个采样数大小乘以这个系数即可。下面给出任意采样频率1通道的8位到16位的部分代码:
//这里各个形参各位应该能对应上,这里不做说明
void reSampleBits(unsigned short inBits, unsigned char* inData, unsigned long inLen, unsigned short outBits, unsigned char* &outData, unsigned long &outLen, unsigned long freq, unsigned short channels)
{
outLen = (unsigned long)(inLen * (double)outBits / inBits);
outData = new unsigned char[outLen];
int inBitBytes = (int)(inBits / 8);
int outBitBytes = (int)(outBits / 8);
unsigned long inSamplePonits = inLen / (inBitBytes * channels);
unsigned long outSamplePonits = outLen / (outBitBytes * channels);
unsigned char* ptInData = (unsigned char*)inData;
unsigned short* ptOutData = (unsigned short*)outData;
for (unsigned long i = 0; i < outSamplePonits; i++) {
unsigned char retLow = 0;
unsigned char retHigh = 0;
if ((ptInData[i] & 0x80) == 0x80) {
retLow = 0x00;
retHigh = (unsigned char)(ptInData[i] - 0x80);
}
else {
retLow = 0xff;
retHigh = (unsigned char)(ptInData[i] - 0x80);
}
ptOutData[i] = retHigh;
ptOutData[i] <<= 8;
ptOutData[i] |= retLow;
}
}
至此三种参数变化的重采样方法已进行说明,如果有多个参数需要同时适配,这里各需要组合即可。这里之所以没有把代码给全,也希望各位体谅下作者的知识产权,不过后面会发布在本人的云平台上,也请各位期待吧!
什么是混流?混流就是把两段音频数据混在一块进行播放处理,但是两段音频数据能混在一起的前提条件是这两段音频数据的属性参数(采样率,通道,位深)得是一样的,才可以混在一块进行播放,所以这时如果两段音频属性不一样的话,需要先对这两段音频进行重采样。那么音频属性一致之后再怎么进行处理呢?主要有两种方法处理,一种是平均值法(相对简单);一种是加权计算法(相对麻烦)。平均值法,就是把各采样点数据相加除以流路数即可,这种方法的好处是简单,不用考虑振幅溢出问题,弊端是整体音量会减小;加权计算法,又有多种方法,得看具体的权值计算,这种方法的好处是混合后音量基本不变,弊端是处理麻烦,需要考虑溢出问题(即滤波)。下面给出平均值混流代码片段:
unsigned long outSamplePonits = (ulLen - unHeaderLen) / samplePointSize;
unsigned int* ptOutData = (unsigned int*)&this->m_lpMemData[unHeaderLen];
for (unsigned long i = 0; i < outSamplePonits; i++) {
int lowChannel = 0;
int highChannel = 0;
int soundCount = 0;
for (auto sound : this->m_setMemMulti) {
unsigned long samplePonits = (sound->ulLenRe - unHeaderLen) / samplePointSize;
unsigned long realSamplePonitsLen = samplePonits - sound->nOffsetBytes / samplePointSize;
if (i < realSamplePonitsLen) {
unsigned int* ptData = (unsigned int*)&sound->ptDataRe[unHeaderLen + sound->nOffsetBytes];
short lc = (short)ptData[i];
short hc = (short)(ptData[i] >> 16);
lowChannel += lc;
highChannel += hc;
soundCount++;
}
}
ptOutData[i] = (unsigned short)(highChannel / soundCount);
ptOutData[i] <<= 16;
ptOutData[i] |= (unsigned short)(lowChannel / soundCount);
}
增减益又叫音量大小变化,上面说过改变音量大小就得改变音频波形的振幅,也就是改变采样点的位深值,在增大或减小的时候需要考虑边界值。这里说下两种特殊情况,静音,所有采样点位深值为0即可。至于最大音量是没有的,并不是说你把所有采样点的振幅值调整到最大值,音量就最大了,调整音量的时候得保证等系数变化,尤其在增大的时候,还得考虑溢出问题,不然声音听得不顺耳啊。下面给出音量调整代码片段:
unsigned long samplePonits = (sound->ulLenRe - unHeaderLen) / samplePointSize;
unsigned int* ptData = (unsigned int*)&sound->ptDataRe[unHeaderLen];
unsigned int* ptDataBak = (unsigned int*)&sound->ptDataReBak[unHeaderLen];
double coe = sound->nVolume / 100.0;
for (unsigned long i = 0; i < samplePonits; i++) {
unsigned short lowChannel = unsigned short((short)(ptDataBak[i]) * coe);
unsigned short highChannel = unsigned short((short)(ptDataBak[i] >> 16) * coe);
ptData[i] = highChannel;
ptData[i] <<= 16;
ptData[i] |= lowChannel;
}
技术拓展及应用?
音频技术有哪些?针对windows操作系统提供的技术见下:
- mci:支持混音播放,mp3格式,wav格式。支持麦克风采集
- wave:支持混音、混流播放,wav格式,pcm数据流。支持麦克风采集
- DirectSound:支持混音、混流播放,wav格式,pcm数据流。支持麦克风采集
- DirectMusic:本人没用过,该技术已淘汰
- DirectShow:支持混音播放,wav格式
- CoreAudio:支持混音、混流播放。支持麦克风采集,声卡采集
- XAudio:本人没用过,该技术常服务于XBox游戏主机
- PlaySound:支持文件、流播放,不支持混音播放。wav格式,wav流
- midi:支持文件播放。支持声乐合成录制。wav格式
上述就是本人知道关于音频相关的技术,并且都对其封装过。各有优缺点,难易程度也不相同。不过最后都会发布在本人的云平台上,也请各位关注本人微信公众号便于掌握实际情况。
那么既然我们知道了上述的音频处理技术,那么这些东西到底如何运作于实际。这里需要说明的一点是,技术和产品不要对等,在我们实际面临的产品都是由相关技术交错组合而实现,但呈现出来的东西却可能一眼看不出由哪些技术实现,这或许是技术人员的通病(之所以这样说,主要因为和本人所接触的同事有关,这里没有贬低谁的意思,请各位不要多想,嘿嘿)。需要在产品经理把复杂需求划分成各个子需求时,才知道到底使用哪些技术实现。下面我结合几款市面上的软件进行剖析,给各位分享一下音频技术如何运用于这些产品的。
teamviewer这款产品可以远程操作桌面,共享桌面以及视频会议等。具体样子参见下图:
那么该产品中的远程桌面和共享桌面中的声音采集是采集操作系统的声卡声音,这里就可以使用CoreAudio采集声卡数据,考虑到采集的数据是原始音频数据(即PCM数据)很大,对其先进行编码后再发送至远程端,然后远程端收到数据后先解码,在使用上述技术进行播放即可;那么视频会议功能就是录制每个人的说话声,可以通过使用DirectSound采集麦克风数据,接下来的操作就和刚才说的处理采集的声卡数据过程一样。这是用于音视频传输方面
别踩白块儿&节奏大师这两款产品是游戏,很多人都玩过,属于音乐游戏。参见下图:
尽管这两款游戏没有给出PC版,但现在如果要在PC实现这两款游戏到底如何去做?这两款游戏核心难点就是声音和节奏把控,别踩白块儿相对节奏大师更容易一些,每次按下一个键位就发一下声,玩过这款游戏的应该知道每次触发的声音就是钢琴声音,那么知道这个就好办了,标准钢琴键位88个键位,只需分别录制88个键位的音频键位声音即可,并保存至wav或mp3文件,然后根据一定的策略计算出当点击哪个黑块触发那个键位音(使用上述说的技术进行播放)。而节奏大师每个关卡都是一首歌,有伴奏版和人声版,这个只需要我们去网上下载即可,无需自己录制。我们仔细观察可以发现,没关都会从上至下划过很多节奏符,如果刚好在最下面的触发条上点击节奏符则会弹出Perfect特效字样,但实际并不会有新的声音触发,只是恰好赶上了bgm的节奏点而已。所以我们只需要将bgm进行拆分,以时间为变量,哪个时刻触发哪种节奏符,每种节奏符持续时长,然后为触发条设置不同的触发范围,分别对应不同的等级(perfect、great等),这样就可以实现节奏大师的效果了。需要说明的是,本人这里给出的只是实现思路,真正编写起来并非易事!所以希望各位不要被误导,只有有了思路这些产品实现才成为了可能。
模拟钢琴这是一款钢琴模拟器,参加下图:

模拟器就是原有设备并不支持,但可以这原有设备模拟出你想要的的设备。就像很多PC版的安卓模拟器,让PC也可以运行安卓app;所以钢琴模拟器也是让PC上也能弹奏钢琴。那么要实现出这样的声乐模拟器可不是一件易事,难点不在于技术,在于要懂声乐和各种乐器。就说这个钢琴模拟器,可不能像前面所说的别踩百块二那样录制88键位音就行了,因为真实的钢琴是支持调音的,而且每个键位随着按下的力度和速度发出音也不一样,延音长短也不一样。所以为了能实现这一一款钢琴模拟器并且能演奏上一曲,那么我们得先简单补充下相关知识。在音乐中常用八度音阶表示,在简谱中就是1234567(1上加一点),因为这里没有符号表示,所以我在这就用文字叙述了。就是一个音组中的一个音阶位置到相邻音组中的相同位置的音阶叫做八度音阶,每个音组有7个音阶。在五线谱中常用CDEFGAB表示,这是和简谱中对应的,那么标准钢琴88键是由52个白键和26黑键组成,一共包含2个不完整音组和7个完整音组,每个完整音组一共12个音阶(5个黑键和7个白键),白键对应完整音阶,黑键对应半号音阶。第五个音组的第一个白键就是中央C键,也就是对应简谱中的1,在演奏时一般以这个为基准。下面先给各位简单看下简谱和五线谱:

要想能演奏这种曲谱,首先必须得看懂。所以这里就需要知道节拍,音节,音符类型,音阶类型等相关的音乐知识。所以。。。我在这里就不想详细说明了,这还只是简谱和五线谱,如果你想演奏打击类乐器,如架子鼓或爵士鼓,就得会看鼓谱。顿时是不是感觉,就学个音技术而已,哪来的那么多幺蛾子,哈哈。对,要想写好程序就得知道这么些幺蛾子。
那么上面只是简单说了写相关的音乐知识,要想实现演奏和乐器模拟器程序,需要使用midi技术,windows提供的很全,支持128中乐器,128中音阶,针对打击乐器,支持47中音阶,最多支持16通道,也就是部分大型交响乐曲也可以使用PC模拟或录制噢。所以提供的乐器很丰富。不仅如此,还可以使用期演奏录制(类似录音棚)。本人也写了一个曲谱模拟器,暂不开源,文章最后只给出演奏程序案例(演奏曲:飞鸟和蝉)。
介绍完了音频数在几款产品中的实际运用,后面在和各位分享下人工智能中的语音合成、识别相关知识以及调音师职业,嘿嘿
我这里说的语音合成包含了两种情况,就是文字转音频,音频转文字。文字转音频简单的做法就是将中文汉字的每个汉字录制一个音频文件,那么通过解析文字的时候然后映射相关的音频,并且最后一句完整的音频文件。这样会有弊端,就是说话像机器人,断句节奏啥的没有。市面上有节奏哟感情的语音合成我想大概是使用模拟器做的,肯定不是midi,因为midi无法合成人声。音频转文字,也可以用上述的方法去做,但是精度不高。因为中间需要过滤静音和杂音而且还得考虑多音字,所以在这里本人也只是给出的简单方案。
语音识别现有的实现方法是先将语音转成文字,然后通过语义识别(都是人工智能相关知识,这里对原理不进行说明,想深挖自行摸索),给出下文,在将下文文字转成音频。之所以这样做,我觉得文字数据相对直接操作音频数据来说计算量小。此前在最强大脑综艺节目中,百度研发的语音识别机器人想识别人的声纹,结果准确率并不高,所以通过音频数据直接进行识别还有待后者一起研究。
调音师相对来说更偏向于应用,我们常在哔站看各种鬼畜,把一个角色声音改变成两外一个角色的声音。这个如果你了解上述音频技术之后,你或多或少知道如何用程序实现了。每个人都有不同的声音,这个叫音色不同。我们也知道每个声音都根据频率,位深决定。也就是说我们如果要想将某个声音变成另外一种音色,我只需要知道其频率,然后根据位深进行修改即可。所以说,耳听为虚。。。(因为你的声音可以复制噢)。
上面说的一些技术,我说的很简略。只能说可行,但实现起来可能需要花费很大功夫,我也是和各位分享一下音频相关的技术,以及实际运用。尽管上述说的一些技术,现在已经有很好的产品实践了,但要实现真正意义上的智能,路还很遥远。。。
我一直觉得会弹钢琴的女生优雅,会打架子鼓的男生俊秀,懂音乐的程序员当然最可爱啦,哈哈。愿与各位同僚共勉之!
- 说明
- 分类:驱动研发
- 点击数:62
在日常生活中,声音是人们进行信息传递的重要媒介,为了保证信息的顺利传递,突破距离的限制,往往需要对声音信号进行放大,扩音系统应运而生。
扩音系统是指把声音信号进行实时放大的系统,主要由麦克风、放大器以及扬声器组成,在演奏厅,大教室,会议室等大空间场所得到了广泛应用。但是,扩音系统自使用以来,常常伴随着啸叫问题,极大地影响了用户的使用体验感。啸叫现象是指音频信号通过扬声器播放后,经过一定的传播路径,再次被麦克风拾取,经过放大器的处理后,最后经由扬声器播放,倘若在 “扬声器-麦克风-扬声器”的闭环电路中,存在某种正反馈导致某些音频频率发生自激振荡,就会产生啸叫现象。

啸叫的产生会掩盖正常语音,给人的听感也不好,而且啸叫频点能量很高,严重时甚至能破坏会议中的扩声设备,因此我们需要对啸叫进行抑制。
我们以单通道扩声系统为例说明啸叫产生原理,系统模型如下所示:

该扩声系统由麦克风、功率放大器和扬声器组成,其中G是功率放大器,F是声传播路径,v(t)和x(t)分别为声源信号和反馈信号,y(t)是麦克风的输入信号,u(t)是经过功率放大器处理后的声信号。
根据奈奎斯特稳定准则,当闭环系统的某个角频率w的回路响应的幅度和相位同时满足以下两个条件时,就会引起系统的不稳定,从而引起啸叫。

其中G(w)为放大器的频率响应,F(w)为声传播路径的频率响应。总的来说,产生啸叫必须同时满足振幅条件:反馈增益大于1。相位条件:声源信号的相位和反馈信号的相位是相同的。因此啸叫抑制技术实际上就是破坏啸叫产生的幅度要求或者相位要求。
研究人员针对啸叫抑制主要提出了两大类方法,被动抑制的方法和主动控制的方法。
被动抑制啸叫的原理是减少直达和反射声,我们可以根据声场特性,从声场布局、声场调整、扩音系统设计、扩音设备选型等方向抑制啸叫。主要包括:
(1)从室内建筑声学、如室内的装修,装修材料的选择等方向来抑制啸叫,具体的方法诸如:摆放更多的桌椅,安装天花石膏吊顶,选择吸声材料作为装修材料等等。
(2)合理地摆放麦克风和扬声器:将麦克风和扬声器置于不同的声场显然是最好的方法,可以破坏正反馈,避免啸叫,但这种方法难以实现。因此我们可通过选择合适的麦克风和扬声器的摆放位置来抑制啸叫,如让麦克风尽量不要正对扬声器。
(3)选择合适的扩声设备,如尽量选用低敏感度、高指向性的麦克风。
但是,这种方法只是被动地抑制啸叫,造价和施工难度太大,不具有普遍推广意义。
相较于被动抑制啸叫的方法,主动控制啸叫的方法利用数字设备进行实现,造价低,可复制,能够普遍推广。传统且主流的主动控制方法有三种,分别为相位调制法、增益控制法和自适应反馈抵消法。
相位调制法
相位调制法,简单来说就是移频法和移相法,移频法和移相法进行啸叫抑制的原理是把输入信号的频率分量往前或者往后移动,使得输入信号与声反馈信号频率之间的叠加现象消失,或者使声反馈相位和输入信号的相位产生偏差,破坏了啸叫形成的相位条件,从而达到抑制啸叫的目的。该方法算法简单,且对扩声系统增益有明显提升,可以快速实现啸叫抑制,但是对输入信号进行移频或者移相的操作,对信号的音质损失很大,会导致声信号的音质效果变差。
增益控制法
增益控制法通过降低正反馈环路中的增益,破坏了啸叫形成的幅值条件,达到啸叫抑制的效果。根据需要增益值降低的频带宽度的范围,增益控制法分为三类,自动增益控制法(AGC),自动均衡法(AEQ)和基于陷波滤波器的啸叫抑制法(NHS)。当需要将系统增益降低时,AGC会在信号的整个频带范围内降低增益,有些没产生啸叫的频点幅值也会被降低。AEQ会把声音信号分为几个频段,将啸叫频点对应的频段进行增益衰减,整体受影响不大。而NHS是在特定的频率点进行增益控制,采用陷波滤波器的啸叫抑制法只对自激振荡的频率点附近进行增益控制,在啸叫频率点检测准确的情况下,对附近频率的幅值影响比其它两种方法小,并且计算复杂度低。
自适应反馈抵消法
自适应反馈抵消法(AFC)根据输入信号,对声传播路径进行建模识别,从而估计得到声反馈信号,最后在麦克风的输入信号中减去估计出的声反馈信号,从而实现啸叫抑制。目前AFC的关键在于自适应算法的选择,应用较为普遍的是最小均方误差算法(LMS)。理论上如果可以精确地估计出声传播路径,AFC可以完全地消除啸叫。但是扬声器信号和麦克风信号一般具有一定的相关性,会造成一些估计误差,利用噪声信号法、非线性处理法等去相关技术可降低两种信号的相关性,但是去相关技术会导致一定的声信号失真,因此需要根据实际使用场景在去相关和音质之间做一个权衡。
近年来随着深度学习的发展,研究人员提出了基于深度学习的啸叫抑制解决方案,这类算法包含三个部分,特征提取,学习模型和训练目标。通过把啸叫信号和纯净语音信号混合得到的声信号作为训练样本,最终训练出能够抑制啸叫的网络模型。利用深度学习进行啸叫抑制的处理步骤通常是首先获得掺杂啸叫信号的混合声信号作为输入数据,再对混合声信号提取语音特征,根据期望声信号的不同提取不同的特征,常用的特征有时频特征、频谱、梅尔倒谱(MFCC)、Gamma倒谱(GFCC)等特征,之后建立网络模型,网络模型通常是RNN系列的模型及其变种,例如LSTM、GRU等。最后对网络模型进行训练得到一个可以将混合声信号映射为纯净语音信号的网络模型。目前,利用深度学习进行啸叫抑制的技术正在快速发展,希望在抑制啸叫方面能够达到更好的效果。
总的来说,传统方法和基于深度学习的啸叫抑制方法各有优缺点,我们需要根据实际应用场景来选择最合适的方法。
- 说明
- 分类:驱动研发
- 点击数:85
- 说明
- 分类:驱动研发
- 点击数:76
- 说明
- 分类:驱动研发
- 点击数:136
虚拟音频驱动开发通常涉及创建虚拟音频设备驱动程序,以模拟物理音频设备的功能。这种开发通常用于虚拟会议、音频处理、游戏开发等领域。它可能涉及以下方面:
-
驱动程序开发:虚拟音频驱动程序是软件组件,用于模拟音频设备的输入和输出。开发者需要了解操作系统的音频系统和相应的API,如Windows的WASAPI或ASIO,以及Linux的ALSA等。
-
数字信号处理(DSP):开发虚拟音频驱动通常需要掌握数字信号处理技术,以模拟音频效果、均衡和滤波等功能。
-
驱动程序接口:你需要了解如何与操作系统的音频驱动程序接口进行交互,以便虚拟设备可以与应用程序和硬件设备进行通信。
-
音频流处理:了解如何处理音频流,包括音频采样率、位深度、通道数等,以确保虚拟音频设备的正常工作。
-
与应用程序的兼容性:确保虚拟音频设备能够与各种应用程序协同工作,包括音频编辑软件、通讯应用、游戏等。
-
测试和调试:开发后,需要进行严格的测试和调试,以确保虚拟音频设备的稳定性和性能。
请注意,虚拟音频驱动开发是一项复杂的任务,需要深入了解操作系统音频架构和编程技巧
第 1 页 共 2 页




